UPDATE: This post has a follow-up: http://augustl.com/blog/2018/datomic_look_at_all_the_things_i_am_not_doing_cont/
Original post follows.
This is the video that got me into programming:
(This embed should take you directly to 01:52, where it's all at)
It's DHH's epic first Ruby on Rails demo from 2005. His unique selling point (or one of them, at least) was "look at all the things I'm not doing"
At the time, this was ground breaking in its implementation and accessibility. "Convention over configuration" became a thing.
However, a portion of the developer community now seems to agree that hiding all the complexities of large CRUD apps has its trade offs, especially when it comes to large and long running projects. You end up in a situation where you have to be as knowledgeable about the conventions as if you wrote the code yourself.
Whoops!
Any sufficiently advanced technology is indistinguishable from magic. But is magic always bad? Do we like magic, as long as it hits the sweet spot where it is able to remain hidden from us?
Why do Clojure devs despise the magic in Ruby on Rails, but love the magic of auto-promoting persistent data structures?
Let's explore all the things you're not doing when you're using Datomic.
Look at all the data modeling I'm not doing
Datomic has made a decision for you. When inserting data, everything is completely and utterly flat, with no structure.
[:db/add -1 :person/name "August Lilleaas"]
[:db/add -1 :person/age 31]This is it. All you have for writing data are these facts. A fact consists of:
[:db/add
-1 ;; Entity (the id of the thing we're talking about)
:person/name ;; Attribute (defines the type and some other properties)
"August Lilleaas" ;; Value (self evident)
]
;; No table, no nesting, no depth, no ...Any structure comes later, from queries and reads.
Datomic isn't free of data modeling. You have to choose if an attribute has a cardinality of one or many. You need to define the type of your attributes. But the API you get for writing data is extremely limited. There's no structured schema.
So, essentially: Look at all the up front decisions I'm not making about data modeling.
This has one enormous benefit. You create structure when you read, not when you write. Therefore, you get to come up with new ways of thinking about your data arbitrarily, after the fact. This is just a logical conclusion of having all the decisions about structure being put in the query engine, and not the write API. Contrary to traditional databases, where so much structure is defined up-front when you insert the data.
Look at all the time modeling I'm not doing
So you write these facts into the database, and there's almost no structure when you write.
There are 50 ways to get time modeling wrong in a traditional database, and a few ways to get it right. And even when you got it right, maybe your specific implementation of time management didn't cut it so you need to update it. And maybe you didn't add time management to your entire domain, just the crucial parts.
Given Datomic's extremely simple write API, it is able to implement time management for you, without any additional cost of data modeling or query hatching on your part.
So, essentially: Look at all the up front decisions I'm not making about time modeling.
It's difficult to talk about Datomic without at one point mentioning the time model. The writer is single threaded. You get a completely serialized time-line of your writes, without any special coordination or re-ordering happening. There's no such thing in Datomic as "read this thing, write that thing, read this other thing" and have that be inconsistent in any way shape or form. There's no such thing as "isolation level" (alternatively, Datomic is isolation level 9000), and transactions can't see what happens in other transactions. This is fundamentally solved by having only one transaction being processed at a time.
When you query Datomic, you query against what Datomic calls a "database". This is essentially a view of a point in time of the time-line of writes that have occurred so far. This view is completely immutable, and requires no synchronization with the writer process because Datomic is an append-only database with append-only semantics.
Are you thinking what I'm thinking?
Did you notice the detail there that makes Datomic amazing?
You ask Datomic for a "database", and you get an immutable reference to the value of that database at that point in time. You get to hold onto this value forever, no matter how many writes that occur in the future.
Getting it yet?
You get to hold onto a view of the database that's immutable, no matter what happens to it in the future.
This means that it's extremely cheap for Datomic to let you get a view of a previous state of the database. In fact, internally, the API is exactly the same. You get a reference to the database data structure, with a T value (a reference or id to a point in time in the transaction time-line), and all your queries will ensure that you get the data as of that T value.
So it's really cheap to just set the T value to an earlier point in time, say two weeks ago, or whatever, and get a completely immutable and consistent view of the entire database as of two weeks ago.
Woha.
Look at all the consistency management I'm not doing
In that vein, the consistency model in Datomic is also extremely simple. As mentioned above, the writes happen in a single thread, writing one transaction at a time. This is isolation level 9000. There's no extra management to be done on your part to ensure that you use the correct isolation level or that you do things in the correct order to get the expected result or any of that. Datomic is consistent, period. There's no way to screw that up by misunderstandings or bugs made by the developer that uses Datomic in their app.
The only trade-off here is that you need to resort to stored procedures, VoltDB style, when you want to do anything other than setting a value, deleting (retracting) a value, and doing a few built-in operations like compare-and-swap and identity based upsert. If you want to do things like "increment by 10" or "take N from account X and put it into account Y", you need to express this as a transaction function (Datomic's name for stored procedures), written in Clojure or Java, and ship it off to the transactor (Datomic's name for the database server).
Look at all the time management I'm not doing
This is a bit of a minor point, but I still like it. It is an example of the many things that are suddenly fundamentally solved when you have a database that manages time for you.
Exhibit A: Pagination. Pagination has the issue of being a non-atomic operation. You load the first 50 items. Then you go forward, and load the next 50 items. But in between those two fetches of items, the database might have changed. With Datomic, you can have the T value be a factor in your pagination. You can use this to get a consistent view of the database, so that page two is actually page two. You can also run queries to see if your data set has changed since the provided T value, and inform the user. "Click here to update your view of the data to the most recent changes".
Exhibit B: Return values. Let's say you have a method that takes a bunch of arguments and inserts a new thing into your database. What should it return? Maybe just the ID, so we don't force all users of the API to wait for us to reconstruct a view of the thing that was just inserted. With Datomic, however, this is a non-issue. You simply return the ID and a reference to the T-value as of after your insert (which is something Datomic provides automatically). Then it is up to the consumer to do what it wants with the T-value. And this is another example of the extreme agility you get with Datomic. Because time is managed for you, you get to make a whole lot of decisions later on, since you don't have to worry about the rug getting pulled from underneath your feet.
Look at all the event sourcing I'm not doing
This is a big one.
If you're familiar with event sourcing, you might wonder what the big deal is. "One single threaded time-line of writes" is exactly what event sourcing is?
What does Datomic have that event sourcing doesn't?
Answer: An absence of hand written views.
With event sourcing, you have raw data in your stream of events. This data is useless until you create a view of it. A view is typically a left fold reducing function that gets the previous state and the next event in the list passed to it, and returns a new and updated state.
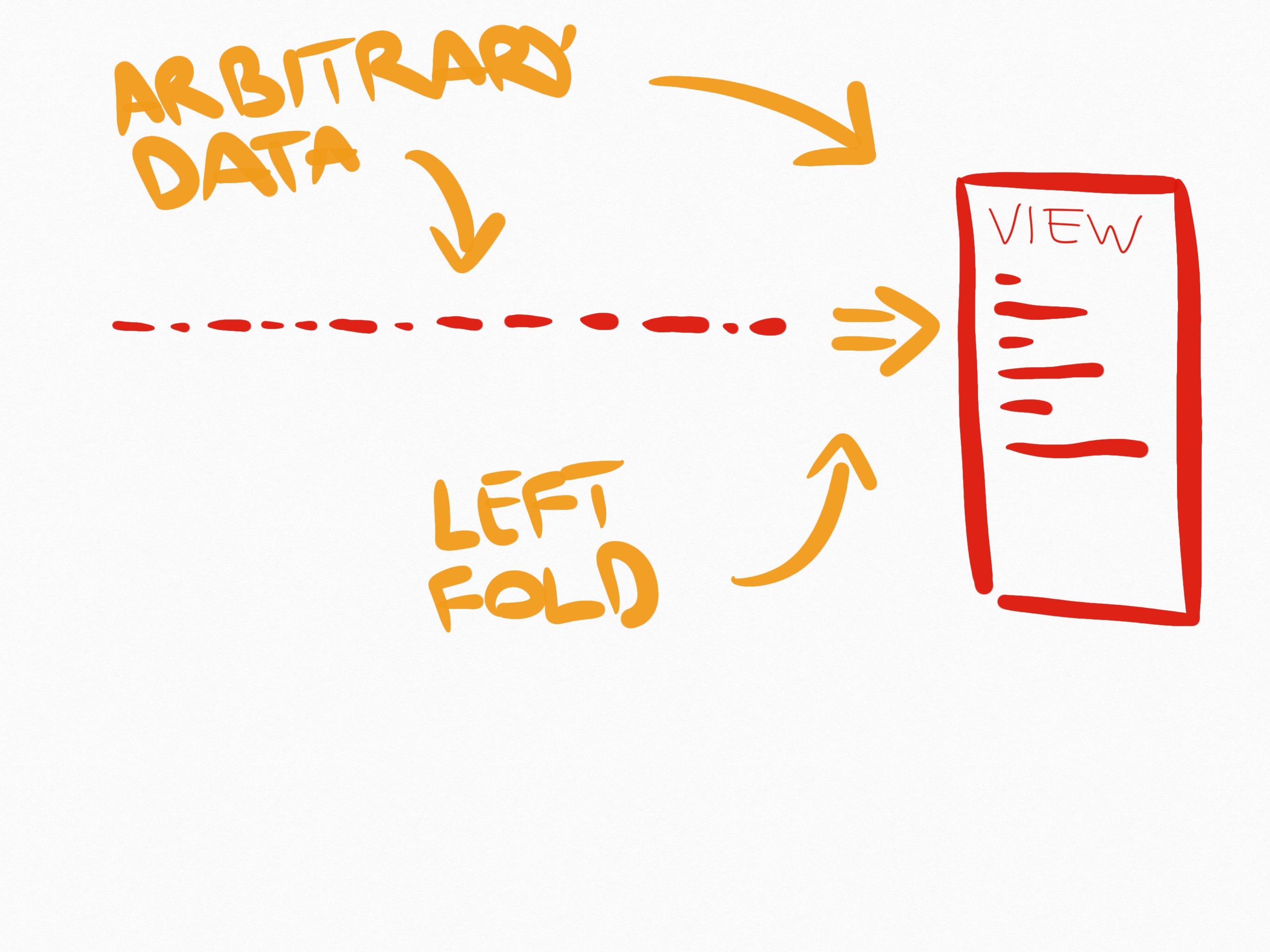
This means that you have to decide which views you want to have. And that if there's a bug in your view code, you have to traverse the entire time-line again to build up the state.
With Datomic, you have the stream of events (facts/transactions), but there is one crucial but fundamentally important difference:
You don't have to decide what your views are up-front
So, essentially: Look at all the up front decisions I'm not making about which views to have.
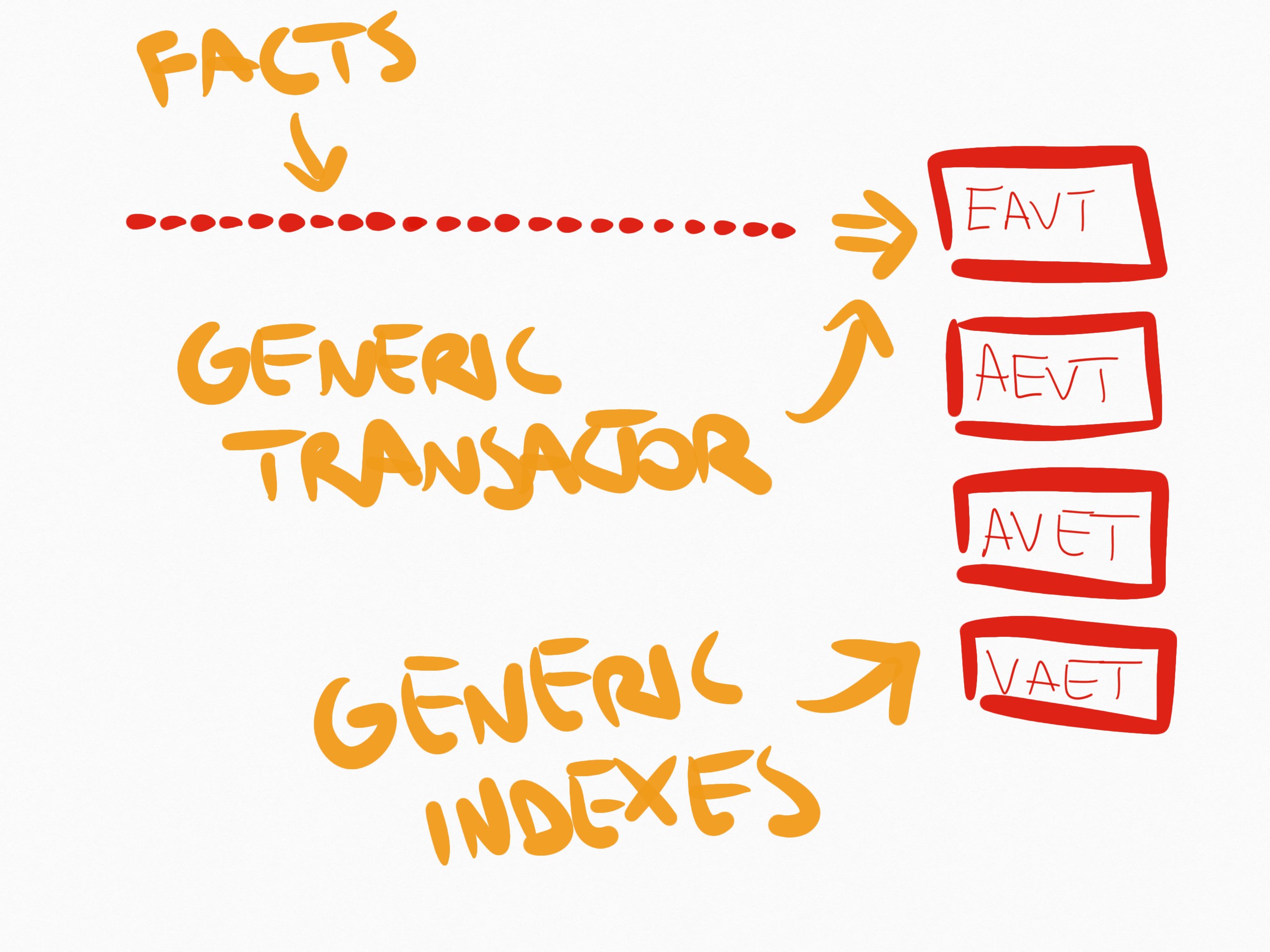
Again, Datomic provides us with extreme agility. Because the data we write is completely flat, but is not arbitrary data but a well known structure (facts), and Datomic have generic indices to query these facts, and because Datomic keeps these indices up to date when we add data to our system, you get the benefits of event sourcing (time travel, a consistent time-line, all your historical data easily traversable), without having to worry about creating views for your data. The views are already there, in form of Datomic's query engine, its built-in time travel features, and efficient indices of historical data.
Look at all the file writing I'm not doing
(Implementation detail)
Internally, Datomic doesn't write to the file system directly. It writes to existing storage engines and databases. You can set up Datomic to write to any JDBC database (mysql, postgres, h2, oracle, db/2, ...), dynamodb, riak + zookeper, and a few other combinations.
This means that Datomic doesn't have to implement its own code for properly writing to disks, which is a huge pain to get right. And it means that if you already use postgres, you don't have to worry about backup routines and operations and what not, other than running the Datomic transactor itself. You can just use your existing routines for postgres operations.
Look at all the database concept reinvention I'm not doing
(Implementation detail)
Datomic doesn't actually invent a whole lot from scratch.
I've already mentioned VoltDB. VoltDB also writes in a single thread, after research revealed that multi-threaded RDBMS databases spend about 75% of their time doing coordination and only 25% of their time actually doing reads and writes. There's this instinct that single threaded processes can't possibly be efficient. But you'd be surprised how much efficiency you can get out of a thread that spends close to 100% of its time doing useful work without much time spent on coordination between multiple threads.
There's also a concept borrowed from Google's Big Table. The indices in Datomic aren't updated live for every write, that would be way too much overhead. So a query in Datomic runs against the latest index + a list of transactions that are written to a transaction log but not yet merged into the index data structures. Then, Datomic will periodically take the unmerged transaction log and merge it into the main index. Big Table does the same, after Google learned that live-merging an index of the entire internet was maybe not going to work.
Look at all the .... ok, I'm done
In my experience, Datomic is indistinguishable from magic, in a good way. It's one level of abstraction above traditional databases, but manages to hide those abstractions since you at no point worry about postgres or zookeeper internals when you make use of Datomic on top of the existing storage engines. You get a whole lot of stuff for free, without Datomic getting in your way.
And to me, the most important point is all of the things you're not doing and all of the decisions you are not making up front, but rather in an agile fashion as your application grows.
Update: even more things I'm not doing
I wrote a follow-up, with even more things I'm not doing:
http://augustl.com/blog/2018/datomic_look_at_all_the_things_i_am_not_doing_cont/